2 O que é Inteligência Artificial (IA)?
O campo da Inteligência Artificial (IA) está fundamentalmente preocupado não apenas com a compreensão, mas também com a construção de entidades inteligentes. Essas entidades são máquinas projetadas para calcular como agir de forma eficaz e segura em uma ampla variedade de situações novas. A própria ideia de inteligência é central para a nossa identidade como Homo sapiens – “homem sábio” – e, por milênios, temos buscado entender como pensamos e agimos, ou seja, como o cérebro pode perceber, compreender, prever e manipular um mundo muito maior e mais complexo do que ele mesmo, como descrevem Norvig & Russell (2021).
No livro Artificial Intelligence: A Modern Approach, os autores adotam a perspectiva da racionalidade como tema unificador. Segundo o que é chamado de modelo padrão, a IA se preocupa principalmente com a ação racional. Um agente inteligente ideal toma a melhor ação possível em uma situação. A abordagem do livro estuda o problema de construir agentes que são inteligentes neste sentido.
Define-se IA como o estudo de agentes que recebem percepções do ambiente e executam ações. Cada agente implementa uma função que mapeia sequências de percepção para ações. A noção de racionalidade pode ser aplicada a uma ampla variedade de agentes operando em qualquer ambiente imaginável. A ideia central é usar esse conceito para desenvolver um conjunto pequeno de princípios de design para a construção de agentes bem-sucedidos.
Um agente racional age para alcançar seus objetivos, dada a informação percebida. A racionalidade se relaciona com a forma como um agente toma decisões em seu ambiente. Para agir racionalmente, um agente precisa ser capaz de:
Processamento de Linguagem Natural (NLP) para se comunicar com sucesso em uma linguagem humana.
Representação do Conhecimento para armazenar o que sabe ou ouve.
Raciocínio Automatizado para responder a perguntas e tirar novas conclusões.
Aprendizado de Máquina para se adaptar a novas circunstâncias e detectar e extrapolar padrões.
Turing considerava que a simulação física de uma pessoa não era essencial para demonstrar inteligência. Entretanto, outros pesquisadores propuseram um Teste de Turing total, que exige interação com objetos e pessoas no mundo real. Para ser aprovado no Teste de Turing total, um robô necessitaria de:
Visão Computacional e Reconhecimento de Fala para perceber o mundo;
Robótica para manipular objetos e deslocar-se.
É importante notar que Aprendizado de Máquina (Machine Learning) é um subcampo da IA que estuda a capacidade de melhorar o desempenho com base na experiência. Embora alguns sistemas de IA usem métodos de aprendizado de máquina para alcançar competência, outros não. O aprendizado é enfatizado tanto como um método de construção para sistemas competentes quanto como uma forma de estender o alcance do projetista em ambientes desconhecidos. Todos os agentes podem melhorar seu desempenho através do aprendizado.
3 De Machine Learning a Agentes de IA: Uma Linha Evolutiva
A jornada da Inteligência Artificial (IA) é uma progressão fascinante. Tudo começou com o Machine Learning (Aprendizado de Máquina) em meados do século XX, focados em algoritmos e modelos que aprendiam padrões em dados para fazer previsões e classificações, sem programação explícita.
Com o tempo e o aumento do poder computacional, o Deep Learning (Aprendizado Profundo) emergiu. Utilizando redes neurais multicamadas, ele revolucionou a capacidade das máquinas de aprender representações complexas de dados, impulsionando avanços em visão computacional e processamento de linguagem.
Mais recentemente, a IA Generativa surgiu, permitindo que modelos de Deep Learning criem conteúdo original – como textos e imagens – a partir de dados de treinamento, indo além da previsão e classificação.
Essa evolução culmina nos Agentes de IA: sistemas que integram aprendizado, geração, percepção, raciocínio e planejamento para agir de forma autônoma em ambientes complexos. Eles representam o auge dessa linha evolutiva, onde a inteligência artificial ganha capacidade de ação e autonomia.
3.1 Machine Learning (Aprendizado de Máquina) e Statistical Learning (Aprendizado Estatístico)
De acordo com a perspectiva apresentada em “Artificial Intelligence: A Modern Approach”, um agente é considerado em aprendizado (learning) se ele melhora seu desempenho após fazer observações sobre o mundo. Quando esse agente é um computador, isso é denominado Machine Learning (ML) (Norvig & Russell, 2021). Em ML, em vez de criar um programa com regras explícitas para mapear entradas para saídas, define-se um programa flexível cujo comportamento é determinado por parâmetros. Um conjunto de dados é utilizado para determinar os melhores valores desses parâmetros, visando aprimorar o desempenho do programa. Isso é conceitualizado como “programar com dados”.
Paralelamente e de forma interligada, existe o campo do Aprendizado Estatístico (Statistical Learning). Autores como Pedro Alberto Morettin e Julio da Motta Singer o associam à utilização de modelos estatísticos acoplados a algoritmos computacionais para extrair informação de conjuntos de dados, frequentemente volumosos. V. Vapnik e Alexey Chernovenkis foram, possivelmente, os primeiros a empregar o termo “Aprendizado com Estatística” (Statistical Learning) no contexto de problemas de reconhecimento de padrões e inteligência artificial (Morettin & Singer, 2024).
3.1.1 Similaridades e Diferenças sob a Perspectiva dos Autores:
Os autores Hastie et al. (2009), estatísticos por formação, declaram terem sido “fortemente influenciados” por campos como redes neurais, mineração de dados e ML. Eles apresentam muitos métodos populares em ML (como Support Vector Machines - SVM, redes neurais, e métodos baseados em árvores como CART por Breiman) dentro da estrutura do Aprendizado Estatístico, e o subtítulo de The Elements of Statistical Learning é “Data Mining, Inference, and Prediction”. Isso indica que veem o ML como um campo cujos métodos podem ser integrados e compreendidos a partir de um ponto de vista estatístico. A necessidade de um tratamento mais acessível desses tópicos levou ao desenvolvimento e publicação, pelos mesmo autores, de livros como Introduction to Statistical Learning, With Applications in R em 2013, com segunda edição em 2021, e An Introduction to Statistical Learning, With Applications in Python em 2023 (James et al., 2021), (James et al., 2023).
Morettin e Singer, estatísticos, observam que grande parte do que hoje é chamado Ciência de Dados e Aprendizado Automático (Machine Learning) consiste na aplicação de técnicas estatísticas que, em muitos casos, já existiam há décadas, mas cuja aplicação em larga escala só se tornou viável com o avanço da capacidade computacional recente. Eles explicitamente usam os termos “Aprendizado Estatística” e “Machine Learning” em conjunto, afirmando que tratam dos mesmos tópicos, com diferenças de interpretação pela abordagem e objetivo (Morettin & Singer, 2024).
Uma diferença fundamental de foco é apontada por Morettin e Singer. Enquanto a Estatística tradicional frequentemente se concentra em entender a associação entre variáveis preditoras e a variável resposta, teste de hipóteses e intervalo de confiança (inferência estatística), o objetivo do ML é, muitas vezes, selecionar o modelo que produz as melhores previsões ou classificações, mesmo que o modelo tenha baixa interpretabilidade (Morettin & Singer, 2024), (James et al., 2021).
Em suma, os autores retratam Machine Learning (ML) e Statistical Learning como campos profundamente interligados e sobrepostos, compartilhando métodos e objetivos de aprender com dados, construir modelos e fazer previsões ou extrair estruturas. O Aprendizado Estatístico pode ser visto como a estrutura estatística subjacente a muitos métodos de ML, com uma tradição que abrange tanto a inferência quanto a previsão/classificação e descoberta de padrões. O ML, impulsionado pela capacidade computacional e com forte ligação à IA e Ciência da Computação, frequentemente enfatiza o desempenho preditivo e a aplicação de algoritmos a grandes conjuntos de dados. No entanto, as fontes deixam claro que muitos dos métodos utilizados em ML são técnicas estatísticas que foram revitalizadas e tornaram-se aplicáveis em larga escala devido aos avanços na computação (Morettin & Singer, 2024), (Hastie et al., 2009).
3.2 Deep Learning (Aprendizado Profundo)
Deep Learning (DL) é um subconjunto do Machine Learning, uma evolução do Machine Learning baseada em redes neurais profundas, com múltiplas camadas ocultas. Permite que máquinas aprendam representações hierárquicas complexas de dados, como imagens, fala e texto. Esses modelos consistem em circuitos algébricos complexos com pesos ajustáveis, tipicamente organizados em muitas camadas, o que significa que os caminhos de computação das entradas para as saídas têm muitos passos (Zhang et al., 2023), (Boehmke & Greenwell, 2019).
Os modelos de Deep Learning incluem diversas arquiteturas especializadas:
- Redes Neurais Densas (DNN): As formas mais básicas, com MLPs (Multi Layer Perceptrons) usando camadas ocultas para aprender relações complexas e não-lineares, ideais para classificação e regressão.
- Redes Neurais Convolucionais (CNNs): Especializadas em dados como imagens, usam filtros convolucionais para detectar padrões locais e hierarquias de características, tornando-as padrão em visão computacional.
- Redes Neurais Recorrentes (RNN): para séries temporais e outras sequências, incluindo LSTM (Long Short-Term Memory), projetadas para dados sequenciais, mantêm “memória” de entradas anteriores. LSTMs são uma variação que aprende dependências de longo prazo, ótimas para texto e áudio.
- Modelos baseados em mecanismos de atenção, como Transformers, que se tornaram dominantes em Processamento de Linguagem Natural: Revolucionaram o PNL com o mecanismo de atenção, processando sequências em paralelo e capturando dependências de longo alcance, sendo a base de grandes modelos de linguagem (LLMs).
- Redes Neurais Bayesianas (BNNs): Incorporam estatística Bayesiana para modelar a incerteza nos pesos da rede, aprendendo distribuições de probabilidade. Isso permite quantificar a confiança nas previsões, sendo úteis onde a incerteza é crucial (ex: diagnósticos médicos).
DL é geralmente uma escolha atraente quando o tamanho da amostra do conjunto de treinamento é extremamente grande e quando a interpretabilidade do modelo não é uma alta prioridade. O DL revolucionou o reconhecimento de padrões em áreas como visão computacional, Processamento de Linguagem Natural (PNL) e reconhecimento automático de fala. Softwares como Keras e TensorFlow são utilizados para implementar modelos de Deep Learning (James et al., 2021), (Morettin & Singer, 2024).
3.3 IA Generativa
IA-Generativa é um Subcampo da IA que utiliza modelos probabilísticos e arquiteturas profundas para gerar novos dados (texto, imagens, vídeos, código) com distribuição semelhante aos dados de treinamento. Diferencia-se de modelos discriminativos por criar conteúdo original em vez de apenas classificar ou prever. Baseiam-se em:
Modelos de Difusão (Diffusion Models): Transformam ruído em dados estruturados através de processos iterativos (ex: Stable Diffusion).
Transformers: Arquiteturas com self-attention capazes de capturar dependências de longo alcance (ex: GPT-4, Claude 3) .
Redes Adversariais Generativas (GANs): Dois modelos competindo (gerador vs. discriminador) para produzir amostras realistas.
É o “boom” atual da IA, revolucionando áreas criativas, educação, programação e produção de conteúdo.
3.4 Agentes de IA (IA Autônoma)
São sistemas mais avançados e integrados que combinam modelos generativos, raciocínio, memória e ação em ambientes interativos. Exemplo: AutoGPT, BabyAGI, Devin. Eles planejam tarefas, acessam ferramentas (buscadores, código, banco de dados), interagem com usuários e adaptam seu comportamento. Representam o estágio mais recente da IA: autonomia e propósito guiado.
4 Aprendizado Supervisionado e Nao Supervisionado
Na área de Machine Learning (Aprendizado de Máquina), distinguimos principalmente duas abordagens de aprendizado com base na natureza dos dados de treinamento: Aprendizado Supervisionado e Aprendizado Não Supervisionado. Zhang et al. (2023) e Géron (2021), definem os seguintes termos desta forma:
4.1 Aprendizado Supervisionado
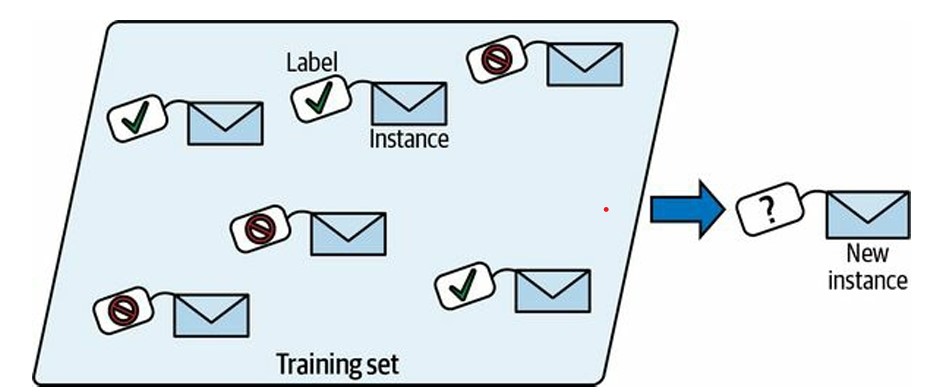
No aprendizado supervisionado, o modelo aprende a partir de um conjunto de dados que contém tanto as características (features, inputs, preditores, atributos, variável independente ou variável de entrada) de entrada quanto os valores de rótulo (target, label, predita, valor-alvo, variável dependente ou variável de resposta) ou classificação correspondentes. É como se o modelo tivesse um “chefe ditatorial” que lhe diz exatamente o que fazer em cada situação até que ele aprenda a mapear situações para ações. O objetivo é encontrar uma modelo que generalize bem para novos exemplos não vistos.
Você fornece ao algoritmo um grande conjunto de dados contendo exemplos de entradas e seus resultados desejados ou rótulos associados. O algoritmo então determina os melhores valores de parâmetros para um programa flexível, de forma a melhorar seu desempenho em relação a uma medida escolhida, usando o conjunto de dados para aprender esse mapeamento. O foco é aprender a prever algo desconhecido (o alvo) a partir de algo conhecido, as características.
4.2 Aprendizado Não Supervisionado
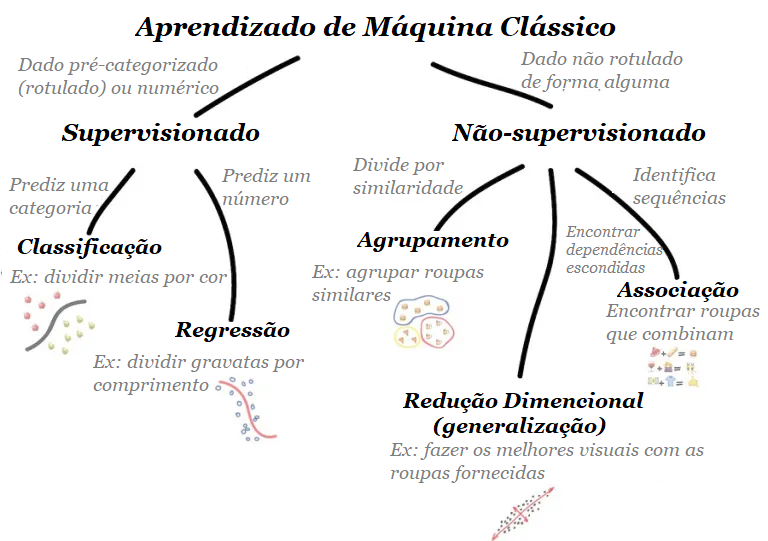
Em Aprendizado não supervisionado os modelos aprendem a partir de dados não rotulados, ou seja, sem orientação explícita sobre quais são as saídas desejadas (não existe variável dependente). Os modelos são usados para descobrir padrões, estruturas e relacionamentos dentro dos dados sem a necessidade de supervisão humana.
O aprendizado ocorre utilizando grandes volumes de dados sem a necessidade de esforço de rotulagem caro. Técnicas como “masked language modeling” preveem partes ocultas do texto usando partes circundantes, gerando a supervisão diretamente dos dados. Isso permite aprender representações (embeddings) para palavras ou textos. Em aprendizado não supervisionado, muitas vezes nos preocupamos com a incerteza, por exemplo, para determinar se um conjunto de medições é anômala ou não.

Comaparção de ambos:
5 Aprendizado Supervisionado (Tipos de Modelos)
5.1 O que é um Modelo?
Um modelo é uma representação abstrata de um fenômeno real, construída com o objetivo de descrever, explicar, prever ou simular comportamentos observáveis. Essa representação pode assumir diferentes formas, desde equações matemáticas simples até estruturas computacionais complexas. A escolha do tipo de modelo depende fundamentalmente do objetivo da análise (predição, inferência ou explicação) e da natureza dos dados disponíveis. Em matemática, estatística e machine learning, modelos traduzem aspectos do mundo em estruturas formais, permitindo análise e tomada de decisão com base em dados.
5.1.1 Modelo Matemático
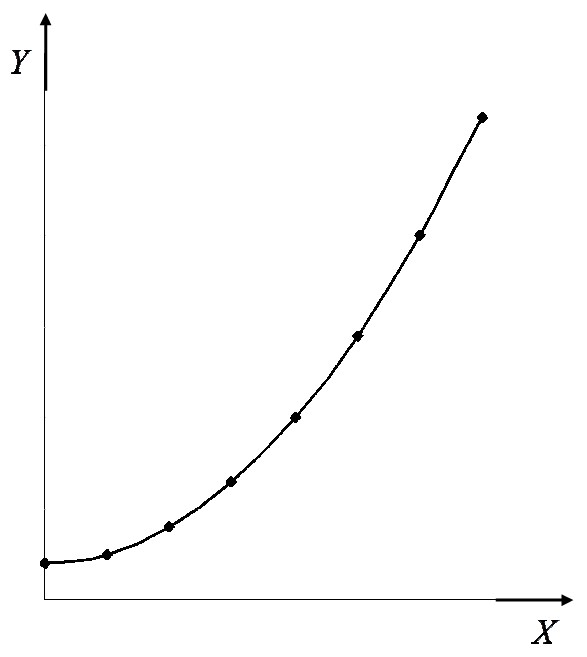
Os modelos matemáticos representam relações determinísticas entre variáveis, sem considerar componentes aleatórios. São amplamente utilizados em física e engenharia, onde as relações entre grandezas são bem compreendidas e podem ser descritas por equações exatas (Hoffmann, 2017).
5.1.1.1 Características principais:
Relações fixas e determinísticas
Não incorpora incerteza ou variabilidade
Parâmetros são constantes conhecidas
Foco em representação exata do fenômeno
5.1.1.2 Exemplo clássico:
Para descrever como a posição de um corpo varia ao longo do tempo, é necessário relacionar cada instante a uma posição correspondente. Essa relação é chamada de função horária da posição e permite prever onde o corpo estará em qualquer momento do movimento. No caso de um movimento uniformemente acelerado, essa função é dada por:
\[ s(t) = s_{0} + v_{0}t + \dfrac{at^{2}}{2} \]
onde:
- \(s(t) =\) posição no tempo \(t\)
- \(s_{0} =\) posição inicial
- \(v_{0} =\) velocidade inicial
- \(a =\) aceleração
- \(t =\) tempo
5.1.2 Modelo Estatístico
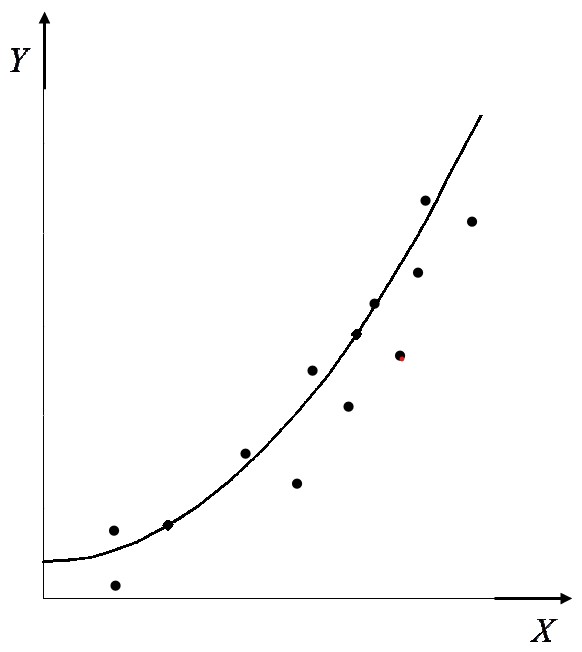
Os modelos estatísticos estendem os modelos matemáticos ao incorporar explicitamente um componente aleatório (geralmente um termo de erro ou resíduo), permitindo lidar com a incerteza inerente aos dados observacionais. São fundamentais em pesquisas científicas onde é necessário quantificar a variabilidade e fazer inferências sobre populações (Hoffmann, 2017).
5.1.2.1 Características principais:
Componente sistemático, ex: \(\mu = g(X; \beta)\)
Componente aleatório, ex: \(\epsilon \sim N(0, \sigma^{2})\)
5.1.2.2 Exemplo - Regressão Linear Múltipla:
\[ Y = \beta_{0} + \beta_{1}X_{1} + \beta_{2}X_{2} + \epsilon, \quad \epsilon \sim N(0, \sigma^{2}) \]
onde:
- \(Y\) = variável dependente
- \(X_{1}\) e \(X_{2}\) = variáveis independentes
- \(\beta_{0}\), \(\beta_{1}\) e \(\beta_{2}\) = coeficientes ou parâmetros
- \(\epsilon\) = componente aleatório
- \(\sigma^{2}\) = variancia
5.1.3 Modelo de Machine Learning
No contexto de machine learning, um modelo é o “maquinário computacional para ingerir dados de um tipo e cuspir previsões de um tipo possivelmente diferente” (Zhang et al., 2023). Os modelos de machine learning muitas vezes se sobrepõem aos modelos estatísticos, ambos são estimados a partir de dados e buscam modelar a relação entre variáveis. O foco em ML pode ser a precisão preditiva em novos dados, mas também a inferência e a compreensão das relações nos dados, especialmente em campos como o Aprendizado Estatístico. Modelos de ML podem variar de métodos lineares interpretáveis (como regressão linear) a modelos complexos e menos interpretáveis, por vezes chamados de “caixas pretas”. No contexto de IA, modelos probabilísticos também são usados para inferência, calculando distribuições de probabilidade sob incerteza (Hastie et al., 2009), (James et al., 2021), (Norvig & Russell, 2021), (James et al., 2023).
5.1.3.1 Principais categorias:
Modelos paramétricos: Assumem forma funcional fixa (ex: regressão linear múltipla)
Modelos não-paramétricos: Forma flexível determinada pelos dados (ex: árvores de decisão)
Modelos semi-paramétricos: Combinação das abordagens
5.1.3.2 Exemplo - Rede Neural Artificial:
\[ \hat{y} = \sigma(W_{2}\sigma(W_{1}x+b_{1})+b_{2}) \]
onde:
- \(\sigma\) = função de ativação ReLU
- \(W_{1}\) e \(W_{2}\) = pesos
- \(b_{1}\) e \(b_{2}\) = bias
- \(x\) = entrada
- \(\hat{y}\) = saída estimada
5.1.4 Comparação Abrangente dos Três Tipos de Modelos
| Critério | Modelo Matemático | Modelo Estatístico | Modelo de ML |
|---|---|---|---|
| Flexibilidade | Baixa | Moderada | Alta |
| Interpretabilidade | Alta | Alta | Variável |
| Tratamento de ruído | Nenhum | Explícito | Implícito |
| Requisitos de dados | Nenhum | Moderados | Altos |
| Complexidade computacional | Baixa | Moderada | Alta |
| Parâmetros | Constantes conhecidas | Estimados dos dados | Aprendidos automaticamente |
| Objetivo principal | Descrição exata | Inferência e predição | Predição e padrões complexos |
| Exemplos | Função horária da posição | Regressão linear | Redes neurais |
Em resumo, um modelo matemático define a estrutura determinística da relação, um modelo estatístico adiciona o componente aleatório necessário para a inferência, e um modelo de machine learning é o sistema computacional estimado a partir de dados para predição e/ou inferência, variando em sua complexidade e interpretabilidade.
5.2 Tipos de Modelos de Aprendizado Supervisionado
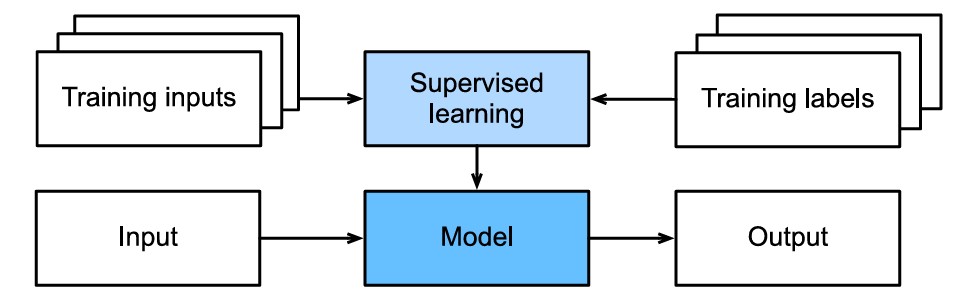
Informalmente, o processo de aprendizagem se parece com o seguinte. Primeiro, pegue uma grande coleção de exemplos cujas características são conhecidas e selecione deles um subconjunto aleatório, adquirindo os rótulos de verdade básica para cada um. Às vezes, esses rótulos podem ser dados disponíveis que já foram coletados (por exemplo, um paciente morreu no ano seguinte?) e outras vezes podemos precisar empregar anotadores humanos para rotular os dados (por exemplo, atribuindo imagens a categorias). Juntos, essas entradas e rótulos correspondentes compõem o conjunto de treinamento. Alimentamos o conjunto de dados de treinamento em um algoritmo de aprendizado supervisionado, uma função que recebe como entrada um conjunto de dados e gera como saída outra função: o modelo aprendido. Finalmente, podemos alimentar entradas não vistas anteriormente para o modelo aprendido, usando suas saídas como previsões do rótulo correspondente. O processo completo é desenhado na figura abaixo (Zhang et al., 2023).
5.2.1 Regressão
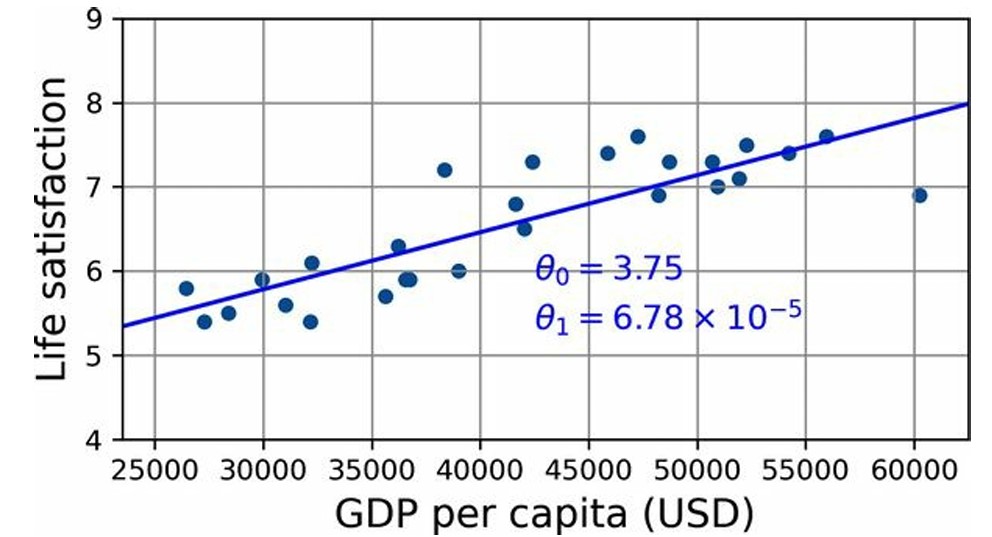
Regressão é uma tarefa fundamental no aprendizado supervisionado. O principal objetivo é prever um valor numérico contínuo . Essencialmente, resolve problemas que perguntam “quanto?” ou “quantos?”. Modelos de regressão são treinados com dados contendo features (entradas) e rótulos (valores numéricos conhecidos). Exemplos comuns incluem prever preços de imóveis ou coordenadas de objetos em detecção de objetos [conversation history, 55]. O treinamento geralmente envolve a minimização de uma função de perda, como o erro quadrático médio (\(MSE\)). Técnicas de regularização são usadas para restringir os valores dos parâmetros e ajudar a evitar o overfitting. Modelos lineares simples podem ser estendidos para Regressão Polinomial adicionando features polinomiais, permitindo que o modelo capture relações não lineares complexas nos dados (Zhang et al., 2023), (Géron, 2021).
5.2.2 Classificação
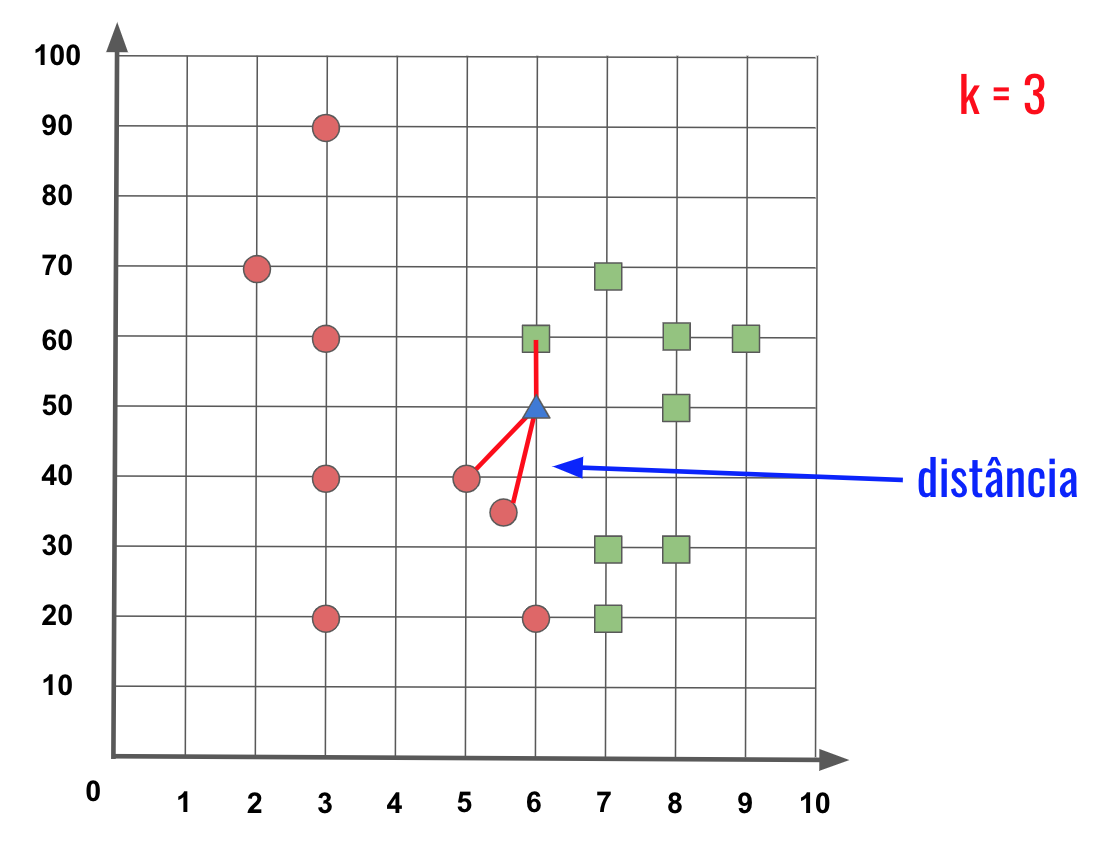
Classificação é uma tarefa fundamental no aprendizado supervisionado. O objetivo principal é prever a qual categoria (classe) discreta um exemplo pertence. Essencialmente, responde a perguntas de “qual categoria?”, diferentemente da regressão (“quanto?”). O modelo utiliza features (entradas) para fazer previsões sobre os rótulos (classes). Existem problemas de classificação binária (duas classes) e multiclasse (mais de duas). Frequentemente, os modelos fornecem probabilidades para cada classe, não apenas uma atribuição única. A função de perda comum usada para treinar modelos de classificação é a entropia cruzada. Exemplos incluem identificar spam em emails ou classificar imagens de objetos ou dígitos escritos à mão. É amplamente usada em Processamento de Linguagem Natural (PLN), como análise de sentimento. Modelos como Softmax Regression, MLPs, CNNs, RNNs e Transformers são aplicados em classificação (Zhang et al., 2023). (Géron, 2021).
5.3 Abordagem de Modelagem: Estatística e Machine Learning
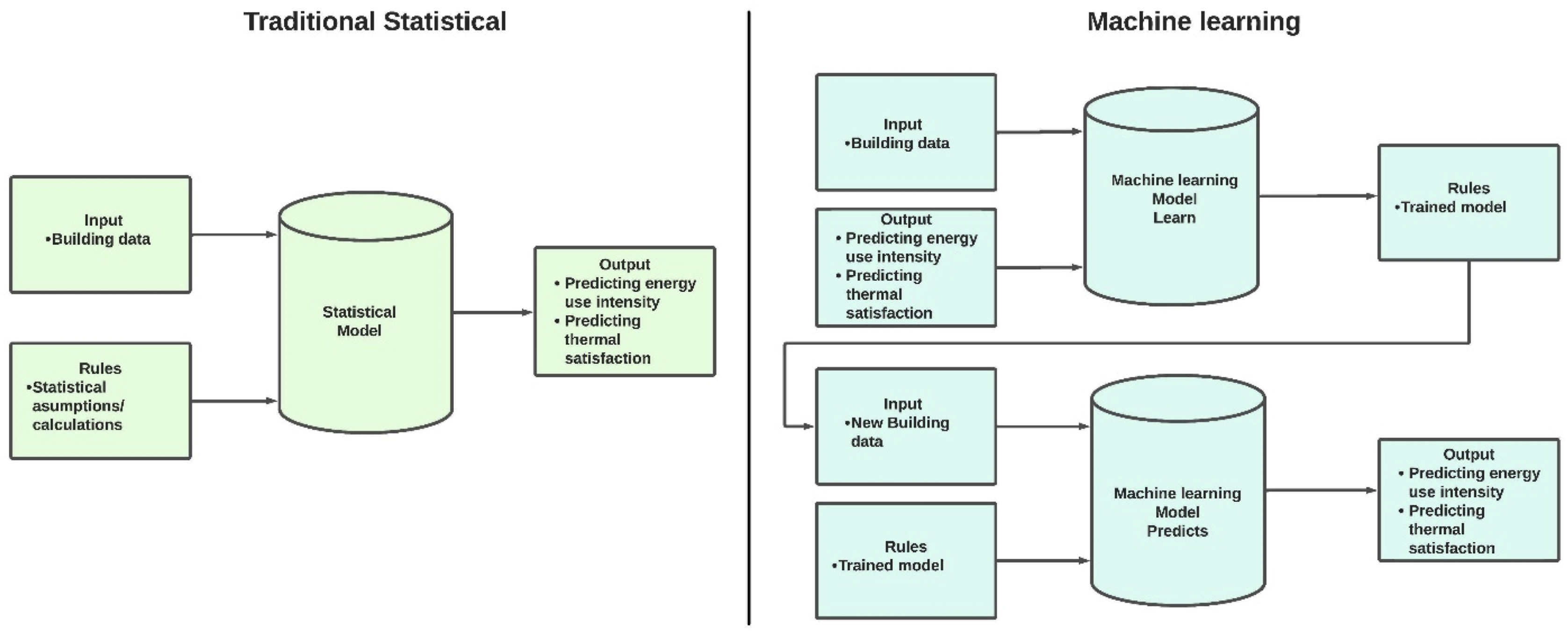
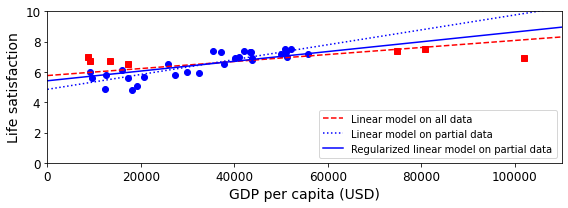
Como descreve Ali et al. (2024), no artigo Uma análise comparativa de aprendizado de máquina e métodos estatísticos para avaliar o desempenho do edifício: uma revisão sistemática e uma futura estrutura de benchmarking, e mostrado na figura acima, a abordagem estatística tradicional utiliza dados para construir uma relação matemática entre as entradas e a saída (variável alvo), levando em consideração suposições e regras estatísticas. Por outro lado, os algoritmos de Machine Learning (ML) aprendem diretamente com o conjunto de dados, identificando padrões que conectam a variável prevista aos preditores, geralmente sem necessidade de suposições rígidas.
Além disso, enquanto o modelo estatístico depende fortemente de conhecimento prévio e transparência no processo, os métodos de ML envolvem o aprendizado e treinamento de algoritmos, funcionando na maioria das vezes como uma “caixa preta” — ou seja, é difícil saber exatamente como o modelo foi formulado. Embora isso permita que o ML capture relações complexas e não lineares sem necessidade de amplo conhecimento de domínio, essa opacidade torna os modelos, em geral, pouco interpretáveis e mais difíceis de explicar.
A figura reforça essas diferenças: à esquerda, a modelagem estatística tradicional segue um fluxo direto, baseado em suposições explícitas; à direita, a modelagem com ML divide-se em fases de aprendizagem e de previsão, mostrando como o modelo precisa ser treinado previamente para gerar um “modelo treinado” que, então, pode ser aplicado a novos dados.
Apesar de suas limitações e custos computacionais elevados, os métodos de ML podem produzir resultados mais robustos em contextos complexos. Assim, é fundamental comparar e avaliar cuidadosamente a adequação de ambas as abordagens. A escolha entre as abordagens depende do objetivo (inferência vs. previsão), da natureza dos dados (linearidade, tamanho) e da necessidade de interpretabilidade do modelo. A integração de ambas as abordagens também é vista como benéfica em muitos campos, como a medicina (Rajula et al., 2020).
6 Parâmetros e Hiperparâmetros
Parâmetro é um elemento fixo que serve para definir, caracterizar ou limitar o comportamento, a estrutura ou as condições de um sistema, processo ou relação. Ele funciona como uma referência ou condição que orienta como algo opera ou se manifesta, independentemente do contexto ou da área de aplicação.
Parâmetro em Estatística: Refere-se a uma característica desconhecida de uma população ou de uma distribuição de probabilidade (Sandoval, 2021), (Hoffmann, 2017). É um valor fixo que descreve alguma propriedade do processo gerador de dados ou da população subjacente. Exemplos incluem a média (\(E(a)=\alpha\)), a variância (\(\sigma^{2}\)), ou coeficientes (\(\alpha, \beta\)) que definem a relação verdadeira em uma população. Esses parâmetros são o alvo da inferência estatística e são estimados a partir de dados de amostra (Morettin & Singer, 2024).
Parâmetro de Modelo: São as quantidades, coeficientes internos ou limiares que definem a forma específica - em modelos matemáticos ou estatísticos - que escolhemos para representar a relação entre as variáveis (Hoffmann, 2017). Em modelos de ML, eles representam a configuração específica de um modelo, e que são aprendidos (ajustados/otimizados) a partir dos dados durante o processo de treinamento (Zhang et al., 2023).
Parâmetros de Algoritmo: São as variáveis declaradas na assinatura de uma função ou método que definem os inputs necessários para sua execução. Representam valores que devem ser fornecidos para que o algoritmo opere corretamente, seguindo sua lógica interna.
def media_aritmetica(valores):
"""Calcula a média de uma lista numérica"""
if not valores:
raise ValueError("Lista vazia não permitida")
return sum(valores) / len(valores)Explicação:
Parâmetro
valores: lista/array de númerosUsa
sum()elen()nativas do PythonLevanta exceção para lista vazia
media_aritmetica <- function(valores) {
if (length(valores) == 0) stop("Vetor vazio")
sum(valores) / length(valores)
}Explicação:
Parâmetro
valores: vetor numéricoUsa
sum()elength()do R baseLança erro com
stop()para vetor vazio
- Hiperparâmetros: Parâmetros de algoritmo de ML (ou, mais comumente conhecidos, hiperparâmetros) podem se referir às configurações ou definições que controlam o processo de aprendizado ou a estrutura do modelo, e que não são aprendidas diretamente dos dados principais durante o treinamento. São definidos antes de iniciar o treinamento principal (Géron, 2021), (Zhang et al., 2023).
from sklearn.ensemble import RandomForestClassifier
# Modelo Random Forest com hiperparâmetros básicos
modelo = RandomForestClassifier(
n_estimators=100, # Número de árvores
max_depth=5, # Profundidade máxima
min_samples_split=2, # Mínimo para dividir nós
random_state=42 # Semente para reprodutibilidade
)
# Treinamento (sem tuning)
modelo.fit(X_train, y_train)Explicação:
n_estimators: Controla o número de árvores na florestamax_depth: Limita a profundidade das árvores (evita overfitting)min_samples_split: Define o mínimo de amostras para dividir um nó
library(randomForest)
# Modelo Random Forest básico
modelo <- randomForest(
x = X_train,
y = y_train,
ntree = 100, # Número de árvores
mtry = 3, # Variáveis por divisão
nodesize = 5 # Tamanho mínimo dos nós
)Explicação:
mtry: Número de variáveis aleatórias em cada divisãontree: Quantidade de árvores no modelonodesize: Tamanho mínimo dos nós terminais
7 Vamos a prática!
O link a seguir levara vocês ao meu github, nele haverá os diferentes notebooks e algoritmos Python e R que usaremos para essa oficina, clique aqui
Referências desse Módulo: